Rosinol 2021 - Kimera - from SLAM to Spatial Perception with 3D Dynamic Scene Graphs 논문 리뷰
논문 요약
이 논문에서는 복잡한 실내 환경에서 지도를 만들고 시간에 따른 변화를 기록하는 프레임워크를 제안한다. 알고리즘 하나하나 다 설명하기보다는, 전체적인 시스템을 설명하는 논문이다.
지도는 scene graph라는 특수한 구조를 가지고 있는데, 공간을 표현하는 방법을 여러 layer로 나누어 단계적으로 표현하는 방법이다. 이 논문에서는 낮은 layer 순서대로 Metric-semantic mesh, Objects and agents, Places and Structures, Rooms, Buildings 순서로 표현한다. 이 중 agents와 같이 움직이는 객체들이 있기 때문에 Dynamic Scene Graph라고 부른다.
가장 낮은 layer에 위치한 metric semantic mesh는 semantic segmentation과 mesh를 생성하는 visual-inertial odometry로 생성한다.
Objects와 Agents를 검출할 때, 움직이는 객체는 agent로, 움직이지 않는 객체는 object로 분류한다. Object를 검출할 때에는 물체의 모양을 알고 있는 경우와 알지 못하는 경우를 따로 분리해서 검출할 수 있다. Agents는 로봇이나 사람 등을 검출할 수 있는데, 논문에서는 사람의 자세를 검출하고 트랙킹 하는 방법을 소개한다.
Places and Structures 및 Room 구분은 바닥/벽/천장을 구분하고 같은 공간끼리 클러스터링하는 방법을 제안한다.

논문 배경
Spatial Perception 시스템이 필요한 이유
로봇이 사람의 수준만큼 공간을 이해하려면 어떤 조건이 필요할까?
- 공간의 기하학적, 의미론적, 물리적 특성을 이해해야한다.
- 물체들 사이의 공간-시간적 현상을 이해해야한다.
- 모든 관계를 단계적으로 이해할 수 있어야한다.
로봇이 공간 속에서 안전하게 이동하고 작업을 하기 위해서는 어떤 기능이 필요한가? 로봇이 사람과 안전하게 상호작용하기 위해서는 어떤 기능이 필요한가?
예를 들어서, 건물에 불이 난 화재 현장에서 소방 로봇에게 ‘2층에서 생존자를 찾아라!’ 라는 명령을 줬다고 해보자. 로봇은 건물 입구에서부터 2층까지 이동하고 탐색을 해야한다. 이를 위해 로봇이 해야하는 작업은 이동 경로를 미리 계획하고, 경로에서 벗어나지 않게 제어를 하며 이동을 하며, 이동 중에는 주변 환경을 실시간으로 인식하며 생존자를 찾아야한다. 사람은 이것을 굉장히 쉽게 할 수 있다 - 후다닥 뛰면서 주변을 두리번두리번 거리면 된다. 현재 기술로는 로봇보다 사람이 작업하는 것이 전체적으로 더 쉽고 저렴하기 때문에 소방로봇보다 소방관이 더 많은 것이다.
공간을 인지하고, 이해하고, 공간 속에서 안전하고 효율적으로 이동하는 것은 사람에게는 굉장히 쉬운 일이다. 로봇의 공간 인지 능력과 이동 능력을 사람의 수준만큼 끌어올리는 것이 자율주행의 핵심이다. 이러한 목표를 달성하기 위해서는 아무래도 사람의 사고 방식을 모방하는 것이 쉬울 수 있다. 사람은 공간에서 공간으로 이동하는데에 어떤 사고 단계를 거칠까?
사람은 로봇과 다르게 High-level understanding을 기준으로 공간을 이해하고 계획하는 경우가 많다. 보스턴에서 로마로 이동을 한다고 할 때, 사람은 집-자동차-운전-공항-체크인-비행기-공항-빠져나오기 와 같은 방식으로의 이동 방법을 계획한다. 이는 로봇이 공간이동을 할 때 사용하는 미터 단위의 움직임 트랙킹과는 아주 다르다. 하지만 사람이 항상 이렇게 topological하게만 생각하는 것은 아니다. 사람도 미터 단위의 움직임을 인식하고, 또 state 변화도 인식할 수 있다. 예를 들어, 멀리 보이는 자동차가 주차되어있는 것인지 아니면 이동하고 있는 것인지 구분할 수 있으며, 사람이 벽을 향해 걸어가다가 방향을 돌리지 않으면 몇초 후에 부딪힐지 예상도 할 수 있다.
이처럼 사람은 동적 객체가 존재하는 복잡한 3D 공간을 굉장히 잘 이해할 수 있다. 몇가지 특징을 분류해보면 다음과 같다.
- 공간의 기하학적 특성을 이해한다. (Geometry)
- e.g. 나와 저 벽은 5m 떨어져있다.
- 공간의 의미론적인 특성을 이해한다. (Semantics)
- e.g. 이것은 의자이다. 저것은 벽이다. 저것은 천장이다.
- 공간의 물리적인 특성을 이해한다. (Physics)
- e.g. 저기 자동차는 주행중이다. 전진 중이기 때문에 갑작스럽게 후진할 수 없다.
- 공간을 여러 단계로 나누어서 이해할 수 있다. (Multiple levels of abstraction)
- e.g. 내 앞의 벽은 3m 떨어져있다. 이 벽은 내 방의 벽이다. 내 방은 우리 집의 일부이다. 우리 집은 우리 동네의 일부이다. 우리 동네는 용인시에 있다. 용인시는 경기도에 있다.
- 객체의 공간-시간적 특성을 이해할 수 있다 (Spatio-temporal relations)
- e.g. 사람이 의자에 앉아있다. 사람이 일어났다. 사람이 앞으로 걸어가면서, 사람과 의자 사이의 거리가 멀어진다.

Geometry / Semantics, Abstraction, Physics / Spatio-temporal relations 관련 연구 리스트
Geometry / Semantics 연구 리스트 (클릭하면 열립니다)
- **SLAM** - [Cadena 2016 - Past, Present, and Future of Simultaneous Localization and Mapping: Toward the robust perception age ]() - **Structure from Motion (SfM)** - [Enqvist 2011 - Non-sequential Structure from Motion]() - **Multi-view stereo** - [Schops 2017 - A Multi-view Stereo Benchmark with High-Resolution Images and Multi-Camera Videos]() - **Semantic segmentation** - [Garcia-Garcia 2017 - A review on deep learning techniques applied to semantic segmentation]() - [Krizhevsky 2012 - ImageNet classification with deep convolutional neural networks]() - [Redmon and Farhadi 2017 - YOLO9000: Better, faster, stronger]() - [Ren 2015 - Faster R-CNN: Towards realtime object detection with region proposal networks]() - [He 2017 - Mask R-CNN]() - [Hu 2017 - Learning to segment everything]() - [Badrinarayanan 2017 - SegNet: A deep convolutional encoder-decoder architucture for image segmentation]() - **Fusion of above** - [Bao and Saverese 2011 - Semantic structure from motion]() - [Bowman 2017 - Probabilistic data associaation for semantic slam]() - [Hackel 2017 - Semantic3d.net: A new large-scale point cloud classification benchmark]() - [Grinvald 2019 - Volumetric instance-aware semantic mapping and 3D object discovery]() - [Zheng 2019 - Active understanding via online semantic reconstruction]() - [Zheng 2019 - From pixels to buildings: end-to-end probabilistic deep networks for large-scale semantic mapping]() - [Davison 2018 - Futuremapping: The computational structure of spatial ai system]()Multiple levels of abstraction 관련 연구 (클릭하면 열립니다))
- **Early researches on map representation in robotics** - [Kuipers 2000 - The Spatial Semantic Hierarchy]() - [Chatila and Laumond 1985 - Position referencing and consistsent world modelling for mobile robotics]() - [Vasudewvan 2006 - Cognitive maps for mobile robots: An object based approach]() - [Galindo 2005 - Multi-hierarchical semantic maps for mobile robotics]() - [Zender 2008 - Conceptual spatial representations for indoor mobile robots]() - **Metric semantic mapping** - [Salas-Moreno 2013 - SLAM++: Simultaneous localisation and mapping at the level of objects]() - [Bowman 2017 - Probabilistic data associaation for semantic slam]() - [Behley - A Dataset for Semantic Scene Understanding fof LiDAR Sequences]() - [Tateno 2017 - CNN-SLAM: Real-time dense monocular SLAM with learned depth prediction]() - [Rosinol 2020 - Kimera: an open-source library for real-time metric-semantic localization and mapping]() - [Grinvald 2019 - Volumetric instance-aware semantic mapping and 3D object discovery]() - [McCorman 2017 - SemanticFusion: Dense 3D Semantic Mapping with Convolutional Neural Networks]()Physics / Spatio-temporal relations 관련 연구 (클릭하면 열립니다))
- **2D Scene graphs** - [Choi 2013 - Understanding indoor scene using 3d geometric phrases]() - [Zhao and Zhu 2013 - Scene parsing by integration function, geometry and appearance models]() - [Huang 2018 - Holistic 3d scene parsing and reconstruction from a single rgb image]() - [Jiang 2018 - Configurable 3d scene synthesis and 2d image rendering with per-pixel ground truth using stochastic grammars]() - **3D Scene graphs** - [Armeni 2019 - 3D scene graph: A structure for unified semantics, 3D space, and camera]() - [Kim 2019 - 3-d scene graph: A sparse and semantic representation of physical environments for intelligent agents]()
3D Dynamic Scene Graph란?
Kimera = 카메라+IMU로 취득한 데이터로부터 공간정보를 인식해서 3D DSG를 생성하는 시스템
5개의 layer로 이뤄짐 - Metric-semantic mesh, Objects and Agents, Places and Structures, Rooms, Buildings
Kimera 시스템의 개발 목적은 인간-로봇의 상호작용을 위한 공간 인식 시스템 (spatial perception)을 만들기 위함이다. 이를 위해 효과적인 공간 표현법이 필요한데, Kimera는 3D Dynamic Scene Graph (3D DSG)를 사용하였다. DSG는 여러개의 계층를 가진 그래프 자료구조)이며, 각각의 node는 공간 객체 (e.g. object, rooms, agents)를 의미하고 각각의 edge는 공간-시간적인 관계를 의미한다 (pairwise spatio-temporal relation).
DSG의 node는 공간 객체를 의미하고, edge는 공간-시간적 관계를 의미한다. Kimera의 DSG는 공간 객체를 표현할 때 1. pose (6dof 방향+위치), 2. shape (형태), 3. bounding box (object detection의 결과인 바운딩 박스)를 함께 표현한다. 또, 각각의 node는 unique ID를 가지고 있으며 (i.e. 독립적이다), 아래와 같은 계층 구조로 표현된다.
- Metric-semantic mesh
- Objects and Agents
- Places and structures
- Rooms
- Building

Layer 1: Metric-semantic mesh
Metric-semantic mesh의 뜻은 다음과 같이 풀어 쓸 수 있다.
- Metric: Meter-ic - 미터-단위의 스케일을 가지고 있는 -> 즉, 실제 세상과 동일한 비율을 가지고 있는 지도를 만든다.
- Semantic: 시맨틱 정보를 가지고 있는 -> 즉, Semantic segmentation의 결과가 함께 적용될 것이다.
- Mesh: 공간을 표현할 때 그래프 형태로 엮여있는 표현 방법 (i.e. 폴리곤 메쉬). Mesh는 node와 edge로 이뤄져있다.
즉, 3D DSG는 ‘실제 세상과 동일한 스케일을 가진 geometry 정보를 mesh로 표현했고, 이 mesh에는 semantic 정보도 함께 담겨있다‘ 라는 뜻이 된다.
Metric-semantic mesh의 node는 각각 다음과 같은 정보를 담고 있다 - 1. 3D position, 2. Normal, 3. RGB 색, 4. Semantic label. Edge를 연결하는 방법은 polygon mesh가 되도록 (i.e. 생성되는 면이 삼각형이 되도록) 만든다.
Metric-semantic mesh는 정적인 물체 (i.e. static)한 정보만 담는다. 예를 들어, 바닥, 벽, 천장, 가구 와 같은 것들이 될것이다. 움직이는 로봇이나 사람과 같이 동적인 물체는 곧 설명할 Agents로써 다루며 metric-semantic mesh에는 포함되지 않는다.

Layer 2: Objects and Agents
Objects
Objects는 건물의 일부가 아닌 정적인 물체를 의미한다. ‘건물의 일부’로써의 예시로는 바닥, 벽, 천장, 기둥과 같은 것들이 있다.
Object node는 다음과 같은 정보를 담고 있다 - 1. 3D object pose, 2. Bounding box, 3. Semantic class. Kimera에서는 여기까지만 저장하지만, 사실 원한다면 더 많이 저장할 수도 있다. 예를 들어, Armeni 2019 - 3D scene graph: A structure for unified semantics, 3D space, and camera 에서는 재질과 같은 정보도 담기도 한다. Node를 이어주는 edge에는 1. co-visibility, 2. 상대적인 크기 차이, 3. 상대적인 거리, 4. 닿아있는지에 대한 여부 와 같은 정보를 저장한다.
모든 object node는 가장 가까운 place node와 연결되어있다 (Place node는 Layer 3에 있다).

Agents
Agents는 동적인 물체를 의미한다. Kimera에서는 주로 ‘로봇‘과 ‘사람‘을 동적인 물체로 분류했다. (논문/코드에서 로봇을 검출&트랙킹 하는 코드는 없고, 사람 검출&트랙킹 관련 부분만 존재한다. 다만, ‘데이터를 수집하는 자기자신’을 로봇으로 인지하긴 한다.)
Agent node는 다음과 같은 정보를 담고 있다 - 1. 시간에 따른 움직임 정보를 담은 3D pose graph, 2. 시간마다 기록해둔 물체의 형태 (사람의 경우, non-rigid mesh), 3. Semantic class (i.e. 로봇인지, 사람인지).

Layer 3: Places and Structures
Places
Place는 ‘비어있는 공간‘을 의미하며, 하나의 node로써 표현이 가능하다. 그리고 이러한 node를 잇는 edge는 place에서 place로 이동이 가능하다는 것을 의미하는 ‘횡단 가능성‘가 (traversability) 되겠다.
Place는 topological 한 성격을 띈다. 이는 place가 다른 하위 node들과 굉장히 다른 성격을 가진다는 것을 의미하는데, 하위 node들은 정확한 위치/형태/크기를 표현하는 geometric한 성격이 강한데에 비해, Place는 단순히 node에 ‘비어있는 공간의 평균 위치’인 3D position 정보만 가지기 때문이다.
이러한 topological 한 성격은 로봇이 움직이는 방법 (i.e. 실제 scale의 occupancy map에서의 경로 계획)이 아닌 좀 더 사람이 움직이는 방법과 유사하게 생각할 수 있게 해준다 (i.e. 1번 place에서 2번 place로 이동한다). 이를 통해 좀 더 효율적인 경로 계획이 가능해지는데, 이 부분에 대해서는 이후 소개할 Hierarchical planning에서 좀 더 다루기로 한다.
Layer 2에 있는 object node들은 해당 object가 검출된 가장 가까운 place에 해당하는 node와 연결이 된다. 또, place node들은 가장 가까운 (Layer 4에서 소개할) room node에도 연결된다.

Structures
Structures는 벽, 바닥, 천장, 기둥과 같은 것들이며, place를 나누는 기준이 된다.
Structure node는 1. 3D pose, 2. bounding box, 3. semantic class 정보를 담고 있다. 구현에 따라, 어떤 방을 감싸고 있는지에 대한 정보도 저장할 수 있다.
Layer 2에 있는 object node가 structure node에 연결이 될 수 있다. 예를 들어, ‘액자가 벽에 걸려있다’ 라던지, ‘전등이 천장에 걸려있다’와 같은 경우에 가능하다.

Layer 4: Rooms
Rooms는 방, 복도, 거실과 같은 공간을 분리하는 기준이 된다.
Room node는 1. 3D pose, 2. bounding box, 3. Semantic class를 담고 있다.
Layer 3의 object node들은 object들이 위치해있는 room node로 연결 된다.
모든 room node는 해당되는 Layer 5의 building node로 연결된다.

Layer 5: Building
Room들을 모아 하나의 빌딩을 만들 수 있다.
Building node에 1. 3D pose, 2. Bounding box, 3. Semantic class 정보를 담을 수 있다.
사실 Kimera 논문에서는 거의 개념만 존재하는 느낌이다. Multi-building 시나리오를 생각하고 만든 것 같지만, 실제로 실험을 진행하거나 하진 않았다.
DSG는 왜 이런 형태를 띄는가?
우리는 5개의 layer로 이뤄진 DSG 구조를 보았다. 각각의 layer의 성격과 layer들관의 관계가 명확하게 정의되어있다. 이게 최선일까? 라는 생각이 들 수도 있다. 저자들은 이렇게 디자인한데에는 2가지 이유가 있다고 한다.
첫째는 Task planning 와 motion planning을 효율적으로 하기 위함이다. 높은 수준의 인간-로봇 상호작용을 위해서는 분명 사람의 사고흐름을 따르는 task가 주어질 것인데, 이는 주로 추상적인 경우가 많다 (e.g. ‘거실에 가서 커피 한잔 타와’). 이에 비해서 로봇의 경로 계획 방법은 기하학적인 움직임을 따르는 경우가 많기 떄문에 (e.g. 0.5 m/s로 3m 전진, 이후 45도 좌회전 후 동일 속도로 2m 전진.) 3D DSG는 상위 layer에서는 semantic 정보를 기반으로 한 topological 한 성격을 띄기 때문에 추상적인 task planning에 효과적이며, 이는 사람의 사고흐름과 비슷하게 경로 계획을 할 수 있다는 것을 의미한다. 상위 layer에서 경로 계획이 끝나면, geometric한 성격을 띄는 하위 layer의 정보에 접근하여 로봇의 경로 계획법을 따라 안전하게 구동부를 작동시킬 수 있다.
둘째는 확정성에 있다. 환경에 따라 places, structures, rooms, buildings와 같은 구조는 적합하지 않을 수 있다. 예를 들어서, 고속도로 같은 환경에는 이와 같은 것들이 전혀 없을 것이다. 하지만 그런 경우에는 몇몇 layer를 제거하고, 적절한 layer로 대체할 수 있다는 장점이 있다. 또, 경우에 따라서, 위/아래로 layer를 추가할 수도 있다. 논문에서 소개하는 3D DSG는 하나 또는 다수의 빌딩을 하나의 그래프 안에 담을 수 있을 것이다. 하지만 이론 상 위에 layer를 계속 추가해서 동네, 구, 시, 나라 까지 엮을 수도 있을 것이다.
Kimera: Spatial Perception Engine 개요
Kimera를 한줄로 표현하면 ‘카메라+IMU로 취득한 데이터로부터 공간정보를 인식해서 DSG를 생성하는 시스템‘이다.
Kimera 시스템은 Kimera-core와 Kimera-DSG라는 2개의 모듈로 나눠진다.
Kimera-Core
Kimera-Core 시스템 오버뷰

Kimera-Core는 실시간으로 metric-semantic mesh를 생성한다.
시스템 인풋으로는 Stereo 또는 RGB-D 카메라, 그리고 IMU를 필요로 한다. 위와 같은 데이터를 통해 Segmentation image, Depth image, RGB image, IMU data stream을 만들 수 있다.
- Kimera-VIO는 Stereo RGB image와 IMU를 받는 VIO 모듈을 이용해서 정확하고 빠른 3D 자세 추정을 수행한다. VIO 모듈은 GTSAM 라이브러리를 통해 IMU pre-integration과 fixed-lag smoothing 기법을 사용한 것이 특징이다. (참고 논문 1, 2). NVIDIA Jetson TX2에서도 실시간으로 동작 가능할 정도로 가볍다.
- Kimera-Mesher는 VIO의 포즈와 맵 정보를 받아 매 프레임 / 다수의 프레임에서 빠른 local mesh을 생성한다.
- Kimera-Semantics는 Kimera-mesher의 결과를 받아 global 3D mesh 생성한다. VoxBlox의 ESDF (Euclidean Signed Distance Function) 기법 사용하며, 3D Bayesian update 방법론을 통해 mesh에 semantic 정보 부여해 metric-semantic mesh를 생성한다.
- Kimera-PGMO는 Loop closure를 이용해 Kimera-Semantics의 global metric-semantic mesh를 최적화한다. PGMO는 Pose-graph and mesh optimization을 줄인 말이다. Kimera-PGMO는 Kimera-RPGO (Robust pose-graph optimization) 라이브러리의 mesh 버전이다.
Kimera-core는 기본적으로 5개의 쓰레드를 사용한다.
- 1번 쓰레드
- Kimera-VIO의 frontend가 stereo image와 IMU 데이터를 인풋으로 받는다. 아웃풋으로 feature track과 pre-integrated IMU 값들을 준다.
- 2번 쓰레드
- Kimera-VIO의 backend가 최적화를 수행하고, 최적화된 맵/포즈 값을 준다.
- 3번 쓰레드
- Kimera-Mesher가 매 프레임마다 3D mesh를 연산하고 (<20ms), 또 여러 프레임 정보를 통합한 3D mesh도 연산한다.
- 4번 쓰레드
- Kimera-Semantics가 metric-semantic mesh를 생성한다. 앞의 3개 쓰레드보다는 상당히 많이 느리게 동작한다. Depth map, 2D semantic label, pose 정보를 필요로 한다. Depth map은 RGB-D 센서에서 바로 얻어내거나, Stereo images에서 dense stereo를 통해 얻어낸다. 2D semantic label은 RGB 이미지에 semantic segmentation을 수행해서 얻어낸다. pose 정보는 Kimera-VIO로 추정한 최적 포즈 값이다.
- 5번 쓰레드
- Kimera-PGMO를 이용해 loop closure를 수행한다. 최적 metric-semantic mesh가 필요하지 않다면 Kimera-RPGO를 사용할 수도 있다.
아래 서브 섹션부터는 각각의 기능들에 대해 상세히 리뷰한다.
Kimera-VIO: Visual-Inertial Odometry
Stereo + Pre-integrated IMU를 이용한 VIO

Kimera-VIO는 카메라와 IMU의 데이터를 혼합하는 visual-inertial odometry (VIO) 기법을 통해 실시간으로 카메라+IMU 시스템의 6dof pose (i.e. 3D 공간 속에서의 방향 + 3D 공간 속에서의 위치)을 추정한다. 동시에, 3D visual landmark를 통해 sparse하게 scene reconstruction을 할 수 있는데, 이 정보를 기반으로 실제 세상과 동일한 scale을 가지고 있는 (i.e. metric-scale을 가지고 있는) mesh를 만들 수 있다.
Kimera-VIO는 현재 많은 VIO 시스템이 채택하는 방법인 keyframe-based 기반 fixed-lag smoothing 기법을 사용한다. 이 방법은 카메라가 취득한 모든 이미지 데이터를 사용하는 것이 아닌, sliding window 기법을 통해 특정 갯수의 keyframe 데이터로부터만 연산을 하는 방법인데, 효과적으로 연산량을 줄일 수 있다는 장점 때문에 2015년 이후 수많은 VIO 기법들이 이와 같은 keyframe-based 기반 fixed-lag smoothing 기법을 사용한다. 물론 더 많은 이미지 데이터를 사용함으로써 정확도를 높일 수 있는 full smoothing 기법도 프로그램 옵션 변경을 통해 사용 가능하다.
내부적으로 사용하는 알고리즘은 다음과 같다.
- Frontend
- IMU preintegration (Forster 2017)
- Shi-Tomasi corner detection (Shi and Tomasi 1994)
- 매 keyframe마다 수행
- Lukas-Kanade tracker (Bouget 2000)
- Initial 값은 IMU rotation 값을 사용 (Hwangbo 2009)
- 매 프레임마다 수행
- left-right stereo match + geometric verification
- Monocular verification -> 5-point RANSAC (Nister 2004)
- Stereo verification -> 3-point RANSAC (Horn 1987)
- Monocular + IMU verification -> 2-point RANSAC (Kneip 2011)
- Stereo + IMU verification -> 1-point RANSAC (Kneip 2011)
- 매 keyframe마다 수행
- Backend
- Preintegrated IMU model + Structureless vision model (Forster 2017)
- GTSAM 라이브러리 (Dellaert 2012) 속 iSAM2 구현을 사용 (Kaess 2012)
Kimera-Mesher: 3D Mesh Reconstruction
Per-frame mesh: 매 프레임 빠르게 mesh 생성
Multi-frame mesh: 여러 프레임의 mesh를 통합해서 생성
Kimera-Mesher는 2가지 종류의 mesh를 만드는 기능을 가지고 있다.
우선 Rosinol 2019 - Incremental Visual-Inertial 3D mesh Generationwith Structural Regularities 논문에서 나온 기법대로 매 프레임 메쉬를 만든다 (논문에서는 Per-frame mesh라고 칭한다). 성공적으로 tracking된 2D feature들을 모아 2D Delaunay triangulation을 한 후, back-projection(역투영)을 통해 3D map에 있는 점들과 association을 수행하여 3D mesh를 생성한다. Per-frame mesh는 정확하지는 않으나 짧은 시간 내에 연산이 가능하기 때문에 간단한 장애물 회피 목적으로 사용할 수 있다.

여러개의 Per-frame mesh를 취합해서 좀 더 정확한 mesh를 만들면 Multi-frame mesh가 만들어진다. 새로운 Per-frame mesh가 만들어질 때 마다 t-1 시점의 Multi-frame mesh와 비교해서 새로운 vertices를 추가한다. 또, VIO backend에서 최적화 연산이 끝날 때 마다 Multi-frame mesh에서 모든 vertices 포지션을 업데이트한다. 또, 오래된 vertices는 삭제한다. Multi-frame mesh는 sliding-window mesh라고 보면 쉽게 이해할 수 있다.

Kimera-Semantics: 3D Metric-Semantic Reconstruction
Bundled raycasting을 이용해서 global mesh 생성. 3D bayesian update를 이용해서 Metric-semantic mesh 생성
Kimera-Semantics는 Global mesh를 만들고 semantic annotation을 하는 기능을 가지고있다.
Global Mesh는 scene 전체에 해당하는 mesh를 의미하며, Voxblox의 bundled raycasting 기법을 사용해서 TSDF (Truncated signed distance field) 모델을 만들어 노이즈를 제거한 후, Marching cubes 알고리즘을 통해 만들어집니다. 이 기법을 사용하기 위해서는 매 keyframe마다 depth map이 필요한데, RGB-D 센서를 사용할 경우에는 depth 센서로부터 이를 취득하고, Stereo 센서를 사용할 경우에는 Dense stereo (i.e. semi-global matching)를 통해 구할 수 있습니다.

Semantic annotation은 global mesh의 vertex마다 semantic class label을 부여해주는 기능을 가지고 있다. Semantic class 추론은 주로 2D semantic segmentation을 통해서 하는데, 다양한 뉴럴넷 기반의 방법이 있겠지만 논문에서는 Mask-RCNN을 사용했다고 한다. 2D label을 3D로 전파하는 방법은 다음과 같다: 1. 2D 이미지에 Semantic segmentation을 수행한다. 2. Global mesh를 생성할 때 스테레오 2D 이미지를 재료로 Dense stereo 기법을 통해 3D point를 만들었을텐데, semantic label을 3D point에 할당한다. 3. Global mesh를 생성할 때 bundled raycasting 기법을 사용했을 텐데, 이 때 ray들마다 semantic class가 몇번 출현했는지를 세어서 label probability를 기록한다. 4. TSDF 연산을 할 때 이 정보도 함께 파싱하고, 이후 매 SemanticFusion에서 사용한 방법과 비슷하게 bayesian update 기법을 통해 voxel마다 semantic clas probability를 연산한다. 5. 가장 높은 확률을 가진 label을 할당시킨다. 이후, Global mesh 생성의 마지막 단계인 marching cubes 기법을 사용해서 최종 metric-semantic mesh를 생성한다. 이 연산 과정은 굉장히 오래 걸리나 (~0.1s), 최종 결과는 multi-frame mesh보다도 훨씬 정확하다.

Kimera-PGMO: Pose graph and Mesh Optimization with Loop Closures
PCM 알고리즘 기반 Loop closure detection. Pose graph + Mesh 최적화
Kimera-Semantics에서 꽤나 정확한 mesh가 생성된다고 해도, 이 mesh는 결국 VIO 모듈에서 에러가 누적된 pose를 (i.e. drift) 기반으로 만들어진 것이기 때문에 global scale에서 부정확한 mesh가 만들어질 것이다. 보통 SLAM에서는 loop closure를 통해 drift를 해결하는데, Kimera에서는 loop closure detection 후 landmark 최적화를 할 때 mesh deformation 모델을 사용한다. 이는 매 최적화 스텝마다 새롭게 mesh를 생성하는 기법이나, point-cloud 로 바꿔주는 de-integration 기법보다는 훨씬 효율적인 방법이다.
Loop closure detection은 Feature-based SLAM에서 많이 사용하는 DBoW2 기법을 사용한다. 기본적인 outlier rejetion을 위해 5-point RANSAC (monocular)과 Stereo 3-point RANSAC을 사용한다. 이후, Kimera의 목적에 맞게 개량한 Pairwise Consistent Measurement Set Maximization (PCM) 이라는 기법을 사용해 추가적인 outlier rejection을 수행한다. Kimera PCM은 기존의 multi-robot 사이의 loop closure를 위한 PCM 기법을, 단일 로봇 odometry의 loop closure로 개량한 것이다.

Kimera PCM은 다음과 같이 동작한다. (절대 그럴리는 없겠지만) drift가 전혀 없다고 했을 때, 이론적으로는 loop closure가 나타난다면 pose들을 쌓았을 때 loop closure가 나타나는 부분은 identity로 포즈가 나타나야한다. 하지만 drift는 항상 존재하는데, Kimera PCM에서는 이 drift를 measurement noise로 취급하여 값을 추적하고 있고, loop closure detection이 수행될 때 이 measurement noise를 Chi-squared test를 통해 ‘drift가 없었다면 factor graph 속 loop의 pose 합들이 identity로 수렴할 것인가?’를 묻는다. 이 테스트를 통과하면 1차 테스트를 통과한 것이다 (논문에서는 이를 odometry check라고 부른다). 2차 테스트는 pairwise consistent check 라고 부르는데, 과거의 loop closure와 현재의 loop closure가 둘 다 같은 loop에 들어있어야만 성공한다는 조건을 건다 (위 그림을 보면 좀 더 이해가 쉽다 - l1와 l2가 둘 다 같은 루프에 들어있어야한다).
성공적으로 Loop closure detection을 수행하면 pose graph와 mesh 최적화를 진행한다. Pose graph만 최적화를 하려면 Kimera-RPGO를, Pose graph와 Mesh 최적화를 하려면 Kimera-PGMO를 사용한다. Mesh 최적화는 deformation 기반의 방법을 사용하는데, 기존의 point cloud 최적화와는 다른 Loss function을 가진다. Kimera-semantic으로 생성된 mesh는 굉장히 촘촘한데, 이를 최적화에 바로 넣기에는 너무 많은 연산량을 요구하게 된다. 연산량을 효과적으로 감소시키기 위해 mesh를 간소화하는데, octree 구조에 mesh 정보를 담고, 동일 voxel에 있는 vertex는 하나로 합쳐버림으로써 mesh 간소화를 진행할 수 있다. 물론, 이 방식은 정확도를 희생해 속도를 얻는 방법이기 때문에, 성능이 좋은 하드웨어 플랫폼을 사용한다면 voxel 크기를 조정해서 정확도를 더 높일 수 있다.


최적화를 위한 Factor graph에는 Mesh vertices와 VIO pose가 node로 있고, Pose-Pose (i.e. odometry), Pose-Mesh_vertex 의 association, Mesh_vertex-Mesh-vertex의 local rigidity association이 edge로 있다. Vertex k의 위치는 Mesh의 coordinate frame에서
Mesh 최적화는 위의 수식을 따른다. X는 VIO 시스템의 pose, g는 mesh 속 vertex의 초기 위치 (i.e. deformation 이전의 위치), Z는 loop closure detection으로 얻은 상대적인 자세 변화 (i.e. relative transformation), R과 t는 뒤에 ^M이 붙을 경우 Mesh의 rotation/translation, ^X가 붙을 경우 VIO pose의 rotation/translation을 의미한다. 총 3개의 값들이 더해져서 최종 Loss를 정의하는데, 각각 다음과 같은 점을 의미한다.
- 첫번째 값: Kimera PCM이 정의하는 loop closure가 이뤄질 경우 누적된 odometry의 오차가 최소화되야한다는 점
- 두번째 값: 연결되어있는 mesh vertices끼리 Local rigidity를 유지해야한다는 점 (i.e. 최적화 과정에서 소수의 vertex가 구조를 깨부수며 튀어나오거나 사라지는 것을 방지한다)
- 세번째 값: 연결되어있는 VIO_pose - Mesh vertices 끼리 local rigidity를 유지해야한다는 점 (i.e. 최적화 과정에서 mesh 전체가 튀어버리거나 pose가 튀어버리는 것을 방지한다)
각각의 값들에 대한 loss는
논문에서는 vio_rotation, vio_translation, mesh_rotation, mesh_translation와 같은 변수들을 아래의 치환식을 통해 SE(3) pose matrix 형태로 바꿈으로써 문제를 좀 더 간단하게 만들었다. 논문에서는 간단하게 만든 이 수식을 ‘augmented pose graph optimization problem’이라고 칭한다 (하지만 사실 치환만 한 것일 뿐, 내용은 크게 바뀌는게 없다).
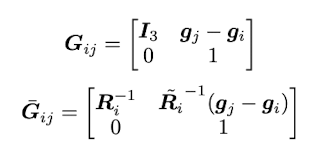
치환식을 거치고나면 기존의 loss 식이 아래와 같이 바뀐다. Z는 모든 odometry와 loop closure edge를 담은 set이 된다. G는 모든 mesh vertex끼리의 edge들의 set을 의미한다.
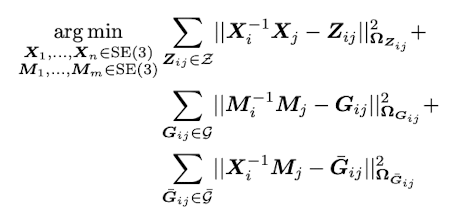
논문에서는 위 수식은 결국 더욱 간단한 형태로 표현된다고 하는데, 솔직히 너무 간단하게 표현해서 정작 중요한 내용은 하나도 보여주지 않는 수식이 하나 있다. T는 pose/mesh vertex의 transformation을, E는 edge의 transformation을 의미하는데, 결국은 ‘이동한 vertex와 edge간의 오차가 최소화되는 SE(3)움직임은 무엇인가?’라는 문제를 푸는 것이다.
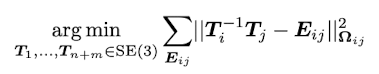
Kimera-DSG

Kimera-DSG는 Kimera-core 종료된 후, Kimera-core가 생성한 3D metric-semantic mesh로부터 비-실시간으로 DSG를 생성한다.
Kimera-Humans는 GraphCMR을 이용해서 사람의 dense mesh를 생성한다. Dense mesh는 Skinned Multi-Person Linear Model (SMPL)을 사용한다. 이후, pose graph model을 이용해서 trajectory를 생성하고 최적화한다.
Kimera-Objects는 1. 사전에 shape을 정확하게 모르는 객체들에 대해서는 bounding box를 추정, 2. 사전에 shape를 정확하게 알고있는 객체 (i.e. CAD 모델이 존재하는 경우) TEASER++를 이용해서 point cloud fitting 및 포즈 추정을 수행한다.
Kimera-BuildingParser는 최상단 3개의 layer를 생성한다. 우선 Layer 3를 생성할 때는 Metric-semantic mesh로부터 structure를 검출하고 places 에 대한 topological graph도 생성한다 (참고 링크). 이후 Layer 3 정보를 기반으로 layer 4를 생성, 이후 layer 4 정보를 기반으로 layer 5를 생성한다.
Kimera-Humans: Humans Shape Estimation and Robust Tracking
로봇 검출: 자기 자신만 트랙킹함
사람 검출: GraphCMR을 통해 SMPL 모델 검출. 다양한 방법으로 안정적인 트랙킹을 수행하며, pose graph 형태로 자세 저장.
Kimera-Humans에는 Robot node와 Human node가 있다.
Kimera 시스템 컨셉에서는 환경에서 여러 로봇들도 함께 존재할 것을 생각했다. 주변 환경에 위치한 로봇을 인식해 Robot node로 등록해 인식하고, 중앙 서버에서 pose graph를 관리함으로써 동시 최적화 및 multi-map SLAM이 가능할 것이다. 이 논문에서는 멀티-로봇 환경을 지원하지 않아 Robot node에는 ‘자기 자신’밖에 없다. 하지만 이후에 나온 논문인 Kimera-Multi에서는 이와 같은 기능을 지원한다.

Kimera 시스템은 사람에 대한 dense mesh와 시간에 따른 이동치를 pose grpah 형태로 표현해서 Human node에 담는다. 사람을 인지하기 위해서는 왼쪽 카메라에서 수행한 2D image segmentation 결과에서 사람이 나온 bounding box를 crop한 후, cropped image에서 GraphCMR 기법을 수행함으로써 SMPL (Skinned Multi-Person Linear Model - 사람의 형태를 가진 dense mesh)를 얻을 수 있다. 이 Dense mesh PnP 기법을 통해서 정확한 pose를 구할 수 있는데, 여기서 사람의 골반뼈 부분을 coordinate frame origin으로 잡아서 pose tracking을 수행한다. SNPL mesh 정보는 Kimera-semantics로도 보내지는데, Metric-semantic mesh를 생성할 때 사람의 mesh는 제거하기 위함이다.
여기서 눈여겨볼점은 ‘어떻게 안정적으로 사람의 움직임을 트랙킹하는가?’이다. GraphCMR은 아주 효과적인 detection 방식이지만, 1. temporal tracking 정보를 전혀 사용하지 않고, 2. partial occlusion이 있을 경우 잘못된 detection을 할 수 있다는 치명적인 단점이 있다. Detection이 불안정하면 자세가 크게 튀기 때문에 안정적으로 트랙킹하는 것이 굉장히 중요하나, 사람의 움직임을 안정적으로 트랙킹하는 것은 생각보다 쉽지 않다. Kimera가 사용하는 방법 중 첫번째 방법은 human pose를 pose graph 형태로 관리하는 것이다. Kimera-RPGO와 PCM outlier rejection 방식을 사용해서 경로가 스무하게 나오게 하고 또 잘못된 트랙킹이 나타나지 않도록 잡아줄 수 있다. 두번째 방법은 굉장히 야매(…)방법이긴 하다 - 새로운 human node가 나타났을 때 주변에 가장 가까운 human node와 이어져있다는 가정을 걸어버리는 것인데, 이는 사람이 생각보다 빠르게 움직이지 않는다는 전제 하에 만든 것이다. 저자들이 참고한 논문에서는 평균 사람의 걷는 속도는 1.25 m/s (Schimpl 2011 발췌)라고 하는데, Kimera에서는 안정적이게 3 m/s로 잡고, 또 관절과 몸통의 거리 차이가 3 m 이상 나지 않는 것을 제약조건으로 두었다. 세번째 방법은 SMPL 모델이 사람의 형태를 정의하는 방법인 beta parameter를 사용하는 것이다. Beta parameter에는 사람의 형태에 대한 8가지 속성이 있는데, 예를 들어 신장이나 어깨 넓이 같은 것들이 있다. 이 정보를 이용해서도 data association이 가능하다. 마지막으로, 애초에 GraphCMR이 잘 동작하기 어려운 환경은 아예 동작을 막아버리는 방법도 있다. Bounding box가 30 픽셀 미만으로 작게 검출될 경우에는 아예 검출 자체를 해버리지 않고, 또 검출이 되어서 pose grpah가 생성되었다고 해도 10개 이상의 node를 지니지 않으면 추후에 DSG를 수행할 때 아예 연산에서 빼버리기도 한다.

Kimera-Objects: Object Pose Estimation
형태를 아는 경우: CAD 모델에서 추출한 point cloud를 이용해서 TEASER++로 point cloud registration
형태를 모르는 경우: Point cloud clustering 후 bouding box 생성
Kimera-Objects는 Metric-semantic mesh로부터 정적인 물체들을 검출하는 기능이다. 사전에 형태를 알고 있는 경우 (Objects with known shapes)와 클래스만 알고 형태는 모르는 경우 (Objects with Unknown shape) 둘 다 모두 검출해서 object node로 넣는다.

형태를 모르는 물체들은 의외로 쉽게 진행될 수 있는데, 이미 metric-semantic mesh에서 semantic한 정보를 가지고 있기 때문이다. 하지만 Mesh 데이터를 순회하면서 다수의 object instance를 떼네 최대한 빠르게 수행하기 위해 metric-semantic mesh 자체를 간단하게 만들 필요가 있다. 우선 PCL 라이브러리에서 지원하는 Euclidean clustering 기능을 이용해서 0.1 m 단위로 mesh를 여러개의 object instance로 만든다. 이후, object centroid를 연산해서 position을 연산, world frame과 동일한 orientation을 할당한 후, 이 정보들을 기반으로 3D bounding box를 연산해서 object node에 저장한다.

형태를 알고 있는 물체들은 pose를 더 정확하게 구할 수 있다는 장점이 있다. 형태를 알고 있다는 것은 주로 CAD 모델을 가지고 있다는 것을 의미하는데, Kimera-objects는 CAD 모델을 3D point cloud로 변환한 후 3D Harris keypoints를 추출한 후, Metric-semantic mesh에 있는 모든 포인트들과 매칭을 해본다. 이 때 연산량이 아주 높을 수 있는데, 정확하고 빠르게 point cloud registration을 수행하기 위해 TEASER++를 이용한다. Registration에 성공하면 object의 3d pose를 정확하게 구할 수 있다.
Kimera-BuildingParser: Extracting Places, Rooms and Structures
Places
Structures
Rooms
Kimera-BuildingParser는 places, structures, rooms를 검출하는 각각의 방법을 담아놓은 패키지이다.
Places를 검출하기 위해서는 우선 Voxblox에서 지원하는 global mesh 재구성법 (i.e. bundled raycasting)과 ESDF 재구성법을 이용한다. 이후 Voxblox의 저자가 적은 논문에서 사용하는 기법처럼 ESDF에서부터 free space를 sparse sampling을 통해 검출하여 topological map을 만든다. Topological map은 그래프 형태로 되어있는데, node는 free space (즉, place)를 의미하고, edge는 traversability (i.e. 이동 가능성)을 의미한다. 이후, 가장 가까운 objects와 agents를 places에 이어준다.

Structures는 이미 Kimera-semantics에서 정보를 다 추출해놓았기 때문에 특별한 검출 단계를 필요로 하지 않는다. 벽 (wall)에 대한 normal 방향을 구한 후, 해당 벽에 대해 가장 가까운 place를 찾아서 연결을 시켜놓은다.
Rooms를 연산할 때는, Kimera-VIO를 통해 얻을 수 있는 중력의 방향을 기준으로 3D ESDF 지도를 cross-section으로 잘라서 2D map을 생성한다. 이 때 천장의 높이보다 0.3 m 정도 낮게 자르는데, 큰 물건들이 벽으로 인식되는 것을 피하기 위해 이러한 휴리스틱을 사용한다. 이 룰을 따라 만든 2D 지도를 우리는 2D ESDF라고 부른다. 이 2D ESDF 지도에서 두께가 0.2 m가 넘는 것들만 남김으로써 문 중턱이라던지 작은 파티셔닝들을 제거한다. 큰 파티셔닝으로 나눠진 공간들로부터 Room을 검출할 수 있게 된다. 아래 그림에서 좌측이 2D ESDF, 우측이 Truncated 2D ESDF 이다.

오픈소스를 하는 사람들이 Kimera에서 배울만한 점
- Jenkins 기반의 CI 서버를 통해 빌드 테스트, 유닛 테스트, 런타임 테스트를 수행한다.
- VIO 디버깅을 위한 정보를 Jupyter Notebook을 통해 확인할 수 있다 (e.g. feature tracking의 품질, IMU preintegration 에러)
- 3D reconstruction의 결과를 Open3D로 볼 수 있다.
실험 결과
VIO 정확도 (RMSE)
많이 사용되는 VIO인 OKVIS, MSCKF, ROVIO, VINS-Mono, SVO 보다 대체적으로 더 좋은 결과를 보여준다.
DVIO는 Kimera가 지원하는 motion estimation 알고리즘 중 5-point나 2-point가 아닌 IMU-aware feature tracking + 2-point stereo RANSAC을 사용한 경우를 DVIO라고 부른다.

VIO + Dynamic Masking
VIO를 수행할 때 주변 환경에 움직이는 객체가 있을 경우 정확도가 많이 떨어지기도 한다.
Kimera에서는 Kimera-Humans를 이용해서 mesh로부터 dynamic 객체에 대한 부분을 제거하기 때문에, 더욱 높은 정확도를 얻어낼 수 있었다는 것을 보여준다.


PCM이 왜 좋은가?
Loop closure를 할 때 PCM은 파라미터를 어떤 것을 설정하던지 좋은 결과를 보인다. PCM을 사용하지 않는다면, scene마다 사용자가 직접 파라미터 튜닝을 해줘야할 것이다.

Global mesh의 정확도
Multi-frame mesh를 기반으로 최적화를 수행해서 global mesh가 되었을 때, 정확도가 대부분의 경우 많이 올라간다.

최종 mesh를 Ground truth 결과와 비교했을 때, 상당히 높은 정확도 + 높은 완성도를 보인다.

사람 검출
수많은 check를 거쳐서 localization error가 꽤 줄어들음.

방 검출
간단한 건축 구조에서는 잘 됨 (좌측)
중앙에 탁자가 있는 방이 복도와 이어져서 다른 방과 연결되는 복잡한 건축 구조에서는 (i.e. 명확하게 문을 통해 분리가 되지 않은 건축 구조) 잘 안됨. (우측)

잘 안되는 곳
논문에서는 종종 정확도가 팍 떨어지는 부분이 있다고 하는데, 주로 stereo 카메라를 사용해서 dense stereo로 depth를 추정할 때 feature가 잘 잡히지 않는 하얀 벽과 같은 곳에서 정확도가 떨어진다고 한다.

속도 (PC)
아쉽게도 컴퓨터 스펙이 안나와있다. 아래 알려져있는 속도 벤치마크이다.

- Kimera-VIO
- IMU preintegration: 40us
- Feature tracking: 7.5ms
- Feature detection, Stereo matching, Geometric verification (Keyframe-only): 51ms
- Kimera-Mesher
- Per-frame 3D mesh generation: 7ms
- Multi-frame 3D mesh generation: 15ms
- Factor graph optimization: 60ms
- Kimera-Objects
- 3 min for ~100m^2
- 12min for ~3000m^2
- Kimera-Humans
- GraphCMR: 33ms (NVIDIA RTX 2080Ti)
- Tracking: 10ms
- Kimera-BuildingParser
- ESDF generatioN: 10 min
- ESDF sparse sampling (i.e. places): 10 min
- Room detection: 2 min
속도 (NVIDIA Jetson TX2)

논문에서는 ‘Kimera는 Embedded device에서도 돌아요!’라고 홍보하지만, 사실상 VIO만 돈다는게 정론.
Kimera-Semantics에 대한 부분도 벤치마크 했다고 하는데, 사실상 Mesh화 알고리즘과 Segmentation도 뺐기 때문에 거의 없다고 보면 된다.
그 외의 DSG 관련 작업은 아예 안돈다고 보면 된다.
MAXN 모드를 사용 (가장 전력을 많이 소비하되, 가장 빠른 모드)
Kimera-Core만 측정했다고 함 (사실 다른건 TX2에서 돌 수 없음 ㅋㅋ)
‘Faster’ config는 fast의 250->200 개 feature만 트랙킹하고, backend optimization도 5->4.5초 window로 줄어들음.
- Frontend: 10ms (Non-keyframe)
- Frontend: 70ms (Keyframe-only)
- Backend: 60ms
- Kimera-Semantics: 65.8 ms
Kimera/DSG의 사용처
아래는 저자들이 추천/생각하는 Kimera / 3D DSG의 사용처이다.
- Obstacle avoidance and planning
- Hierarchical path planning
- Semantic path palnning
- Human-Robot interaction
- Question Answering
- Long-term autonomy
- Prediction
